
Journal of Geographical Sciences >
Enhancing flood risk assessment in northern Morocco with tuned machine learning and advanced geospatial techniques
Received date: 2024-03-21
Accepted date: 2024-09-11
Online published: 2025-01-16
Mapping floods is crucial for effective disaster management. This study focuses on flood assessment in northern Morocco, specifically Tangier, Tetouan, and Larache. Due to the lack of a comprehensive flood inventory map, we used unsupervised learning techniques, such as K-means clustering and fuzzy logic algorithms, to predict flood-prone areas. We identified nine conditioning factors influencing flood risk: elevation, slope, aspect, plan curvature, profile curvature, land use, soil type, normalized difference vegetation index (NDVI), and topographic position index (TPI). Using Landsat-8 imagery and a Digital Elevation Model (DEM) within a Geographic Information System (GIS), we analyzed topographic and geo-environmental variables. K-means clustering achieved silhouette scores of 0.66 in Tangier and 0.70 in Tetouan, while the fuzzy logic method in Larache produced a Davies-Bouldin Index (DBI) score of 0.35. The maps classified flood risk levels into low, moderate, and high categories. This research demonstrates the integration of machine learning and remote sensing for predicting flood-prone areas without existing flood inventory maps. Our findings highlight the main factors contributing to flash floods and assess their impact, enhancing the understanding of flood dynamics and improving flood management strategies in vulnerable regions.
Key words: remote sensing; conditioning factors; GIS; flood susceptibility; machine learning; DEM
MOUTAOUAKIL Wassima , HAMIDA Soufiane , SALEH Shawki , LAMRANI Driss , MAHJOUBI Mohamed Amine , CHERRADI Bouchaib , RAIHANI Abdelhadi . Enhancing flood risk assessment in northern Morocco with tuned machine learning and advanced geospatial techniques[J]. Journal of Geographical Sciences, 2024 , 34(12) : 2477 -2508 . DOI: 10.1007/s11442-024-2301-4
Figure 1 Pictures show the historic of flooding in the northern region in the last few years, (a) TTN on 1/03/2021, (b) TGR on 08/02/2021, and (c) LRC on 05/04/2022 |
Table 1 Dataset overview of three zones in Morocco: geographic, flood, and demographic factors |
| Area of study | Number of rows | Number of conditioning factors | Area (km2) | Mean elevation (m) | Population (habitant)* |
|---|---|---|---|---|---|
| TGR | 186,620 | 8 | 169.58 | 71.56 | 1,060,261 |
| TTN | 102,206 | 90.120 | 43.56 | 547,177 | |
| LRC | 23,689 | 22.28 | 22.35 | 495,030 |
Note: * is according to the High Commission for Planning in Morocco in 2014. |
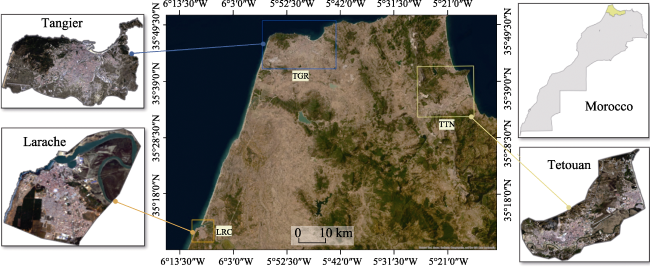
Figure 2 Detailed maps of study areas: three identified regions with square box boundaries in the WGS84- EPSG 4326 coordinate system |
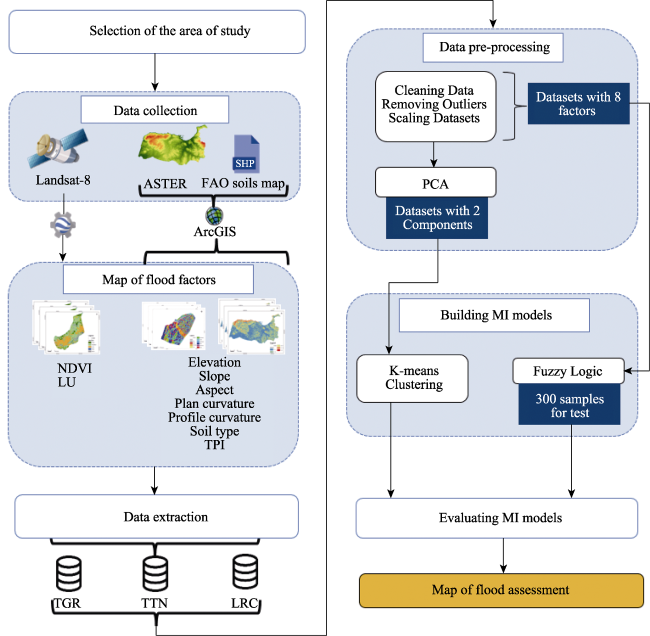
Figure 3 Flowchart of methodology for creating the flood susceptibility |
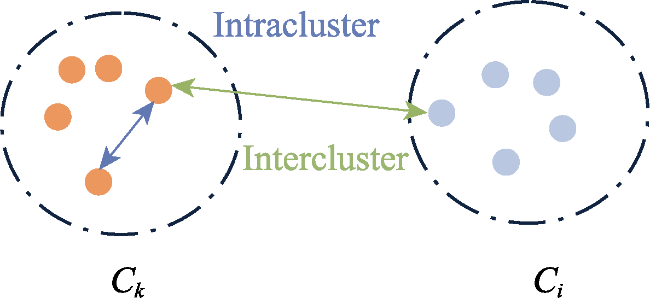
Figure 4 Description of clustering metrics |
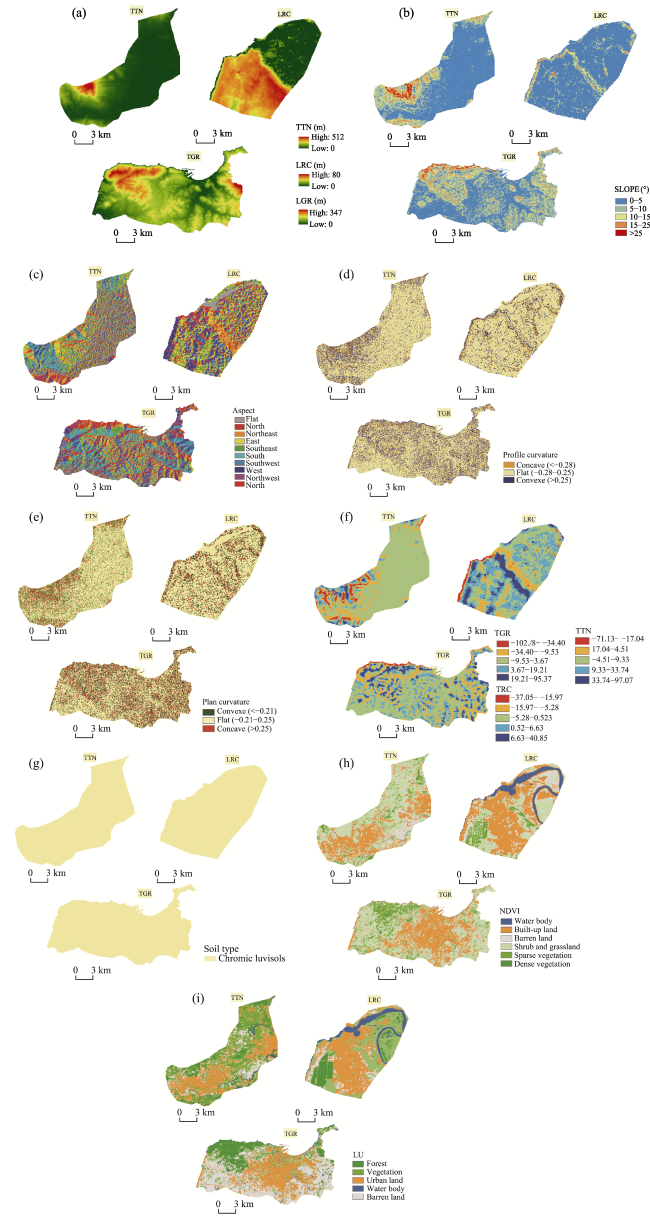
Figure 5 Maps of conditioning factors of the three zones (a. Elevation; b. Slope; c. Aspect; d. Profile curvature; e. Plan curvature; f. TPI; g. Soil type; h. NDVI; i. LU) |
Table 2 Descriptive overview of conditioning factor data sources |
| Conditioning factors | Source of data | GIS data type | Time | Resolution |
|---|---|---|---|---|
| Elevation | DEM | Grid | - | 30 m × 30 m |
| Slope | - | |||
| Aspect | - | |||
| Plan curvature | - | |||
| Profile curvature | - | |||
| TPI | - | |||
| LU | Landsat-8 | From 2016-01-01 into 2022-12-31 | ||
| NDVI | From 2016-01-01 into 2022-12-31 | |||
| Soil type | FAO soils map | Vector | - | - |
Table 3 Parameters description of each unsupervised model |
| ML models | Set of parameters |
|---|---|
| K-means clustering | Number of clusters: {TGR=3, TTN=5, LRC=5}, Random state:{32}, Max iteration: {500} |
| Fuzzy logic method | Membership function: {Triangular}, Coefficient of membership: {Table 4}, fuzzy logic rules: {Table 5}, output names: {low, moderate, high}, output membership: {(0, 0, 50), (25, 50, 75), (50, 100, 100)} |
Table 4 Membership coefficients for flood conditioning factors |
| Environmental variables | Linguistic variables | Coefficient | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| LRC | TTN | TGR | ||||||||
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | ||
| Elevation | Low | 0 | 10 | 20 | 0 | 50 | 100 | 0 | 50 | 100 |
| Moderate | 19 | 35 | 50 | 50 | 250 | 450 | 50 | 150 | 200 | |
| High | 49 | 65 | 85 | 400 | 550 | 600 | 198 | 340 | 340 | |
| Slope | Low | 0 | 10 | 15 | 0 | 10 | 15 | 0 | 10 | 20 |
| High | 15 | 20 | 30 | 15 | 20 | 38 | 20 | 30 | 43 | |
| LU | Forest | 1 | 1 | 2 | 1 | 1 | 2 | 1 | 1 | 2 |
| Vegetation | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | |
| Water body | 2 | 3 | 4 | 2 | 3 | 4 | 2 | 3 | 4 | |
| Urban land | 3 | 4 | 5 | 3 | 4 | 5 | 3 | 4 | 5 | |
| Barren land | 4 | 5 | 5 | 4 | 5 | 5 | 4 | 5 | 5 | |
| Profile curvature | Concave | -2 | -1.4 | -0.28 | -2 | -1.4 | -0.28 | -4 | -1.4 | -0.28 |
| Flat | -0.8 | 0 | 0.8 | -0.8 | 0 | 0.8 | -0.8 | 0 | 0.8 | |
| Convex | 0.28 | 1.4 | 2 | 0.28 | 1.4 | 3 | 0.28 | 1.4 | 4 | |
| Plan curvature | Convex | -5 | -3.14 | -0.21 | -5 | -3.14 | -0.21 | -3 | -3 | -0.21 |
| Flat | -1.12 | 0 | 1.12 | -1.12 | 0 | 1.12 | -1.12 | 0 | 1.12 | |
| Concave | 0.21 | 3.14 | 5 | 0.21 | 3.14 | 3 | 0.21 | 2.14 | 4 | |
| TPI | Valley | -37 | -1 | 0 | -37 | -1 | 0 | -37 | -1 | 0 |
| Flat | 0 | 1 | 7 | 0 | 1 | 11 | 0 | 1 | 11 | |
| Ridge-hill | 6 | 20 | 40 | 6 | 50 | 99 | 10 | 50 | 97 | |
| NDVI | Water body | 1 | 1 | 2 | 1 | 1 | 2 | 1 | 1 | 2 |
| Built-up land | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | |
| Barren land | 2 | 3 | 4 | 2 | 3 | 4 | 2 | 3 | 4 | |
| Shrub and grassland | 3 | 4 | 5 | 3 | 4 | 5 | 3 | 4 | 5 | |
| Sparse vegetation | 4 | 5 | 5 | 4 | 5 | 5 | 4 | 5 | 5 | |
| Dense vegetation | 5 | 6 | 6 | 5 | 6 | 6 | 5 | 6 | 6 | |
Table 5 Some fuzzy logic rule set |
| Rules | Input variables | Output |
|---|---|---|
| 1 | Elevation [‘low’] AND Slope [‘high’] | Risk [‘high’] |
| - | - | - |
| 4 | (Elevation [‘low’] OR TPI [‘valley’]) & LU [‘water body’] | Risk [‘high’] |
| - | - | - |
| 10 | Elevation [‘high’] AND LU [‘forest’] AND NDVI [‘dense-vegetation’] | Risk [‘low’] |
| - | - | - |
| 15 | (Elevation [‘moderate’] OR Elevation [‘high’]) AND NDVI [‘built-up’] | Risk [‘moderate’] |
Table 6 Summary of the assessment outcomes for K-means and fuzzy logic models in each area of study |
| Zone | Model | Categories | DBI | Silhouette score |
|---|---|---|---|---|
| TGR | K-means clustering | Low Moderate High | 0.55 | 0.66 |
| Fuzzy logic | Low Moderate High | 0.51 | 0.56 | |
| TTN | K-means clustering | Very low Low Moderate High Very high | 0.50 | 0.70 |
| Fuzzy logic | Low Moderate High | 0.46 | 0.47 | |
| LRC | K-means clustering | Very low Low Moderate High Very high | 0.58 | 0.62 |
| Fuzzy logic | Low Moderate High | 0.35 | 0.54 |
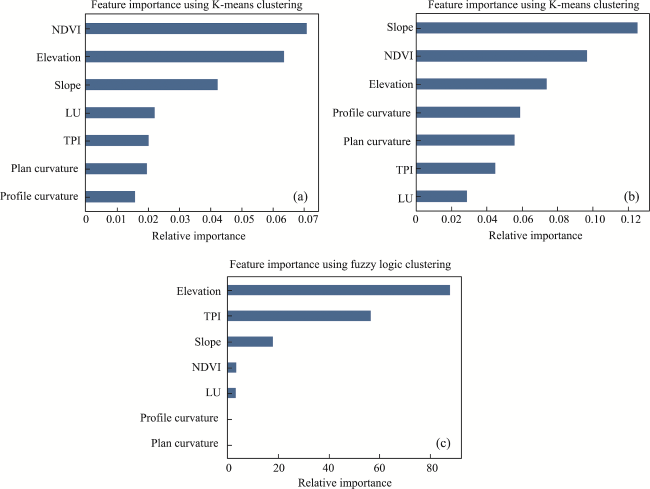
Figure 6 Flood conditioning factor importance using the best model (a. TGR; b. TTN; c. LRC) |
Table 7 Relative importance values recorded using the best model |
| Features | Relative importance (TGR) | Relative importance (TTN) | Relative importance (LRC) |
|---|---|---|---|
| Elevation | 0.06 | 0.07 | 87.84 |
| TPI | 0.02 | 0.04 | 56.62 |
| Slope | 0.04 | 0.12 | 17.97 |
| NDVI | 0.07 | 0.09 | 3.50 |
| Profile curvature | 0.01 | 0.06 | 3.31 |
| LU | 0.02 | 0.03 | 0.14 |
| Plan curvature | 0.02 | 0.05 | 0.11 |
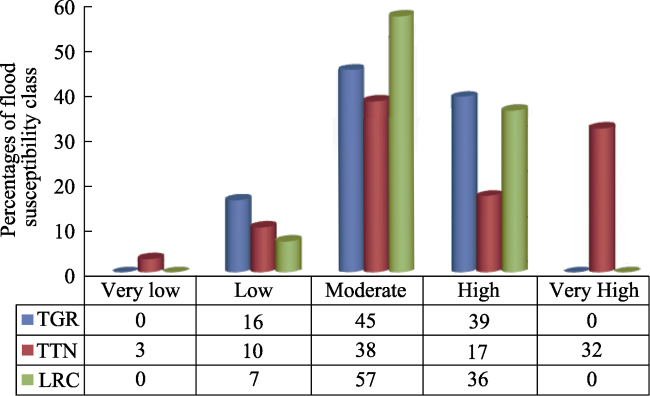
Table 8 Distribution of flood risk levels in TGR, TTN, and LRC |
| Zone | Risk levels | Area (ha) |
|---|---|---|
| TGR | Low | 2678.31 |
| Moderate | 7585.03 | |
| High | 6485.43 | |
| TTN | Very low | 307.48 |
| Low | 863.23 | |
| Moderate | 3542.32 | |
| High | 1485.99 | |
| Very high | 3005.82 | |
| LRC | Low | 65.48 |
| Moderate | 1038.07 | |
| High | 994.48 |
Figure 7 Distribution percentages of flood risk level in TGR, TTN, and LRC |
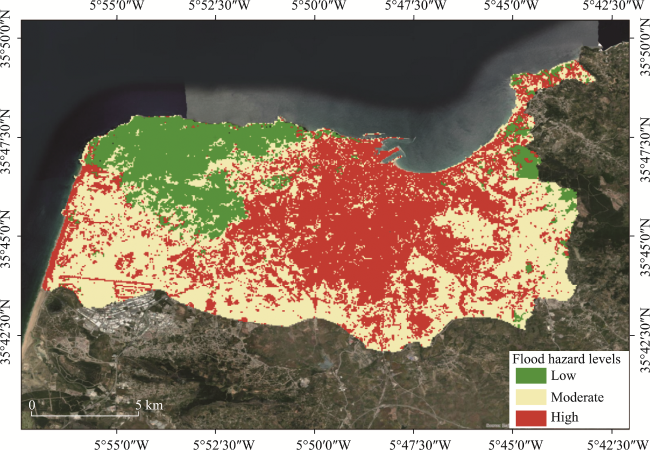
Figure 8 Map of flood hazard assessment in TGR using K-means clustering |
Figure 9 Map of flood hazard assessment in TTN using K-means clustering |
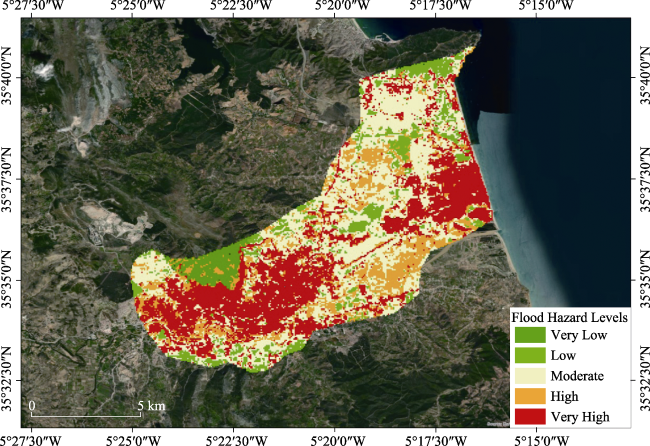
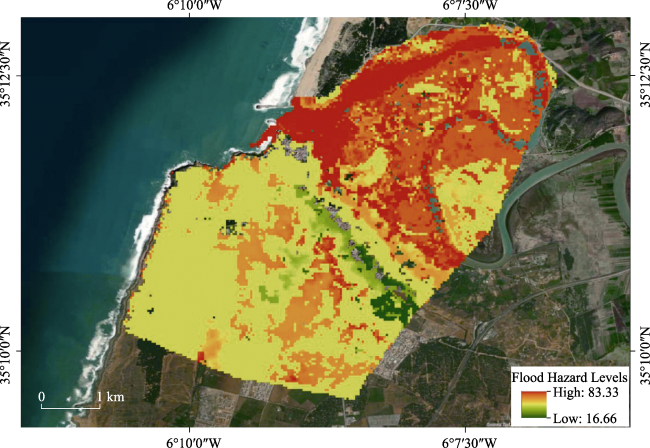
Figure 10 Map of flood hazard assessment in LRC using the fuzzy logic method |
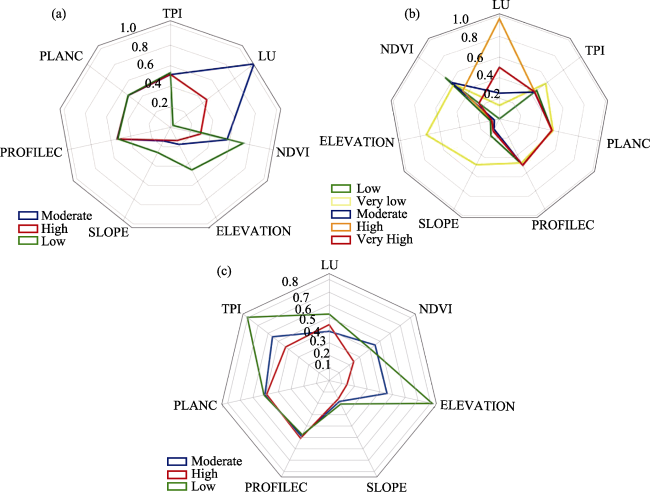
Figure 11 Mean Normalized index values of flood conditioning factors and the risk level identified in each region of study (a. TGR; b. TTN; c. LRC) |
Table 9 Result of comparison between this paper and previous research |
| Related work | Area of study | The best model | Accuracy | Relevant factors | Data source |
|---|---|---|---|---|---|
| (Talukdar et al., 2020) | Teesta River basin, Bangladesh | Bagging with the M5P algorithm | AUC=0.945 | LU/LC | Landsat 8 DEM Climatic data River map |
| (Meliho et al., 2022) | Ourika, Morocco | RF, XGB | AUC=0.99 | Rainfall and slope | DEM Inventory Map |
| (Bouramtane et al., 2021) | Tangier, Morocco | CART SVM | AUC=0.99 | Drainage density, Distance to rivers, and LU | DEM |
| (Talha et al., 2019) | Guelmim, Morocco | FAHP | - | SMI, Rainfall, and Drainage density | Landsat-8 OLI DEM |
| (Sellami et al., 2022) | Tetouan, Morocco | RF | AUC = 0.99 | Elevation, Slope, Aspect, LU/LC, SPI, Plan curvature, Profile, Curvature, TPI, and TWI | Sentinel 2B DEM |
| (Parsian et al., 2021) | Po-e Dokhtar and Nurabad, Iran | AHP & fuzzy logic | AUC=0.95 | Distance to river, rainfall, and elevation | Sentinel-1 DEM |
| (Xu et al., 2018) | Haidian Island, China | K-means clustering | - | Elevation, distance to rivers, and length drainage conduits | Flood inundation model DEM |
| (Janizadeh et al., 2019) | Tafresh Watershed, Iran | ADT | AUC=0.98 | Lithology and Distance to the river | Landsat OLI DEM Local soil map |
| This work | TGR | K-means clustering | DBI = 0.55 Silhouette Score = 0.66 | Elevation, Slope, LU, and NDVI | Landsat-8 DEM |
| TTN | K-means clustering | DBI = 0.50 Silhouette Score = 0.70 | |||
| LRC | Fuzzy logic | DBI = 0.35 Silhouette Score = 0.54 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}