
Journal of Geographical Sciences >
Spatio-temporal prediction of regional land subsidence via ConvLSTM
|
Leng Jing (1997-), Master Candidate, specialized in prediction of regional land subsidence. E-mail: lj906425232@163.com |
Received date: 2022-10-22
Accepted date: 2023-05-16
Online published: 2023-10-08
Supported by
National Natural Science Foundation of China(41930109/D010702)
Beijing Outstanding Young Scientist Program(BJJWZYJH01201910028032)
R&D Program of Beijing Municipal Education Commission(KM202210028009)
Land subsidence is a geohazard phenomenon caused by the lowering of land elevation due to the compression of the sinking land soil body, thus creating an excessive constraint on the safe construction and sustainable development of cities. The use of accurate and efficient means for land subsidence prediction is of remarkable importance for preventing land subsidence and ensuring urban safety. Although the current time-series prediction method can accomplish relatively high accuracy, the predicted settlement points are independent of each other, and the existence of spatial dependence in the data itself is lost. In order to unlock this problem, a spatial convolutional long short-term memory neural network (ConvLSTM) based on the spatio-temporal prediction method for land subsidence is constructed. To this end, a cloud platform is employed to obtain a long time series deformation dataset from May 2017 to November 2021 in the understudied area. A convolutional structure to extract spatial features is utilized in the proposed model, and an LSTM structure is linked to the model for time-series prediction to achieve unified modeling of temporal and spatial correlation, thereby rationally predicting the land subsidence progress trend and distribution. The experimental results reveal that the prediction results of the ConvLSTM model are more accurate than those of the LSTM in about 62% of the understudied area, and the overall mean absolute error (MAE) is reduced by about 7%. The achieved results exhibit better prediction in the subsidence center region, and the spatial distribution characteristics of the subsidence data are effectively captured. The present prediction results are more consistent with the distribution of real subsidence and could provide more accurate and reasonable scientific references for subsidence prevention and control in the Beijing-Tianjin-Hebei region.
Key words: land subsidence; deep learning; ConvLSTM; spatio-temporal prediction; cloud platform
LENG Jing , GAO Mingliang , GONG Huili , CHEN Beibei , ZHOU Chaofan , SHI Min , CHEN Zheng , LI Xiang . Spatio-temporal prediction of regional land subsidence via ConvLSTM[J]. Journal of Geographical Sciences, 2023 , 33(10) : 2131 -2156 . DOI: 10.1007/s11442-023-2169-8
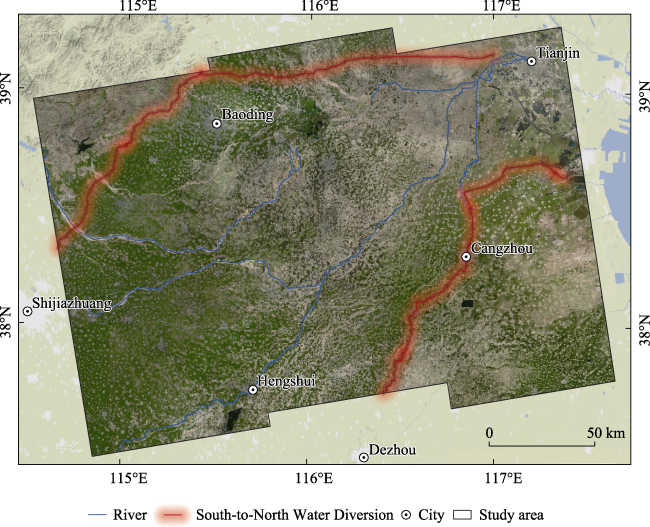
Figure 1 Geographic location of the understudied area in the Hebei Plain |
Table 1 Radar image information |
| Radar image | Sentinel-1A (S1A) |
|---|---|
| Flight direction | Ascending |
| Polarization | VV+VH |
| Band | C-Band |
| Beam mode | Interferometric wide swath (IW) |
| Wave length (cm) | 5.6 |
| Ground resolution (m) | 5×20 |
| Revisit cycle (d) | 12 |
| Number of images (scene) | 132 |
| Time range | 2017.05.20-2021.11.19 |
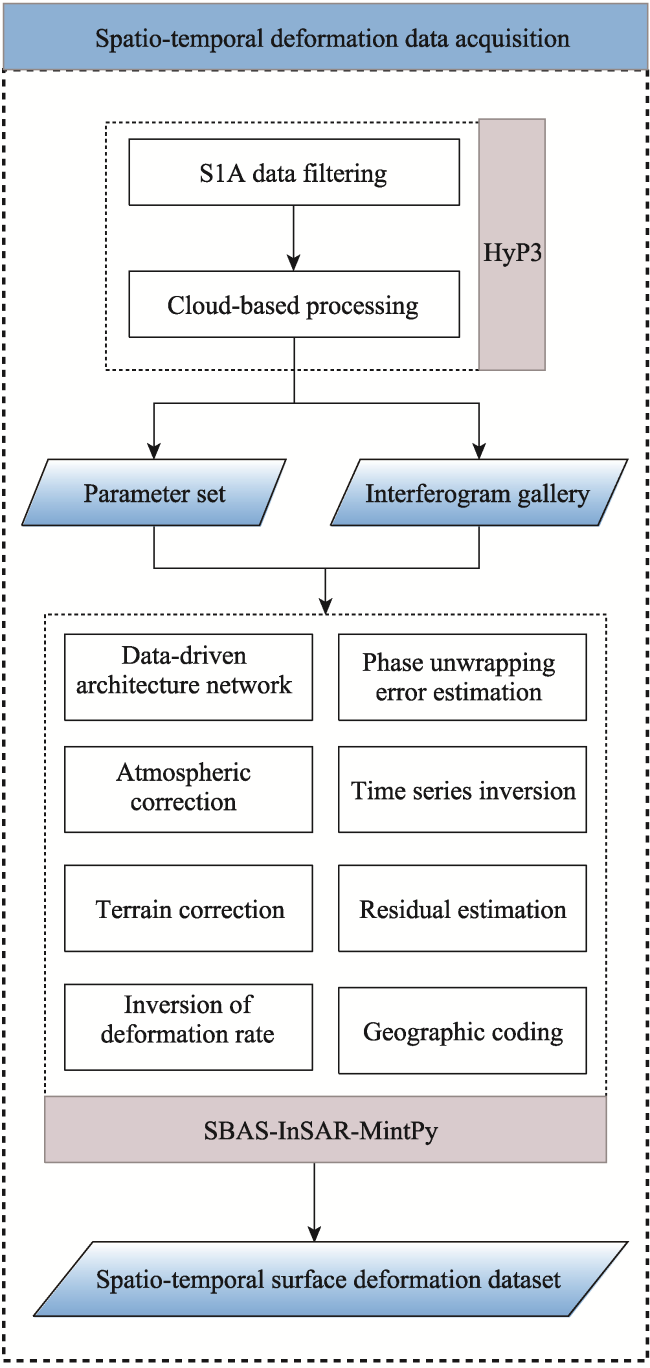
Figure 2 Spatio-temporal subsidence dataset production process |
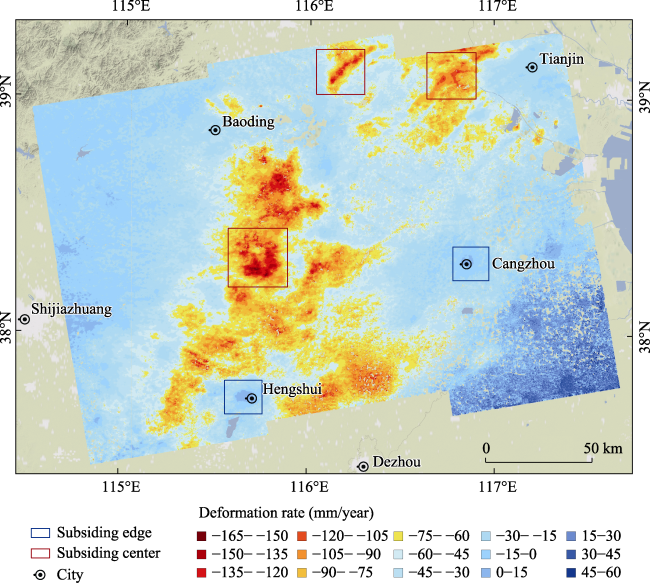
Figure 3 Spatial distribution of land subsidence in the understudied area from 2017 to 2021 (Note: the presented box indicates the typical deformation area.) |
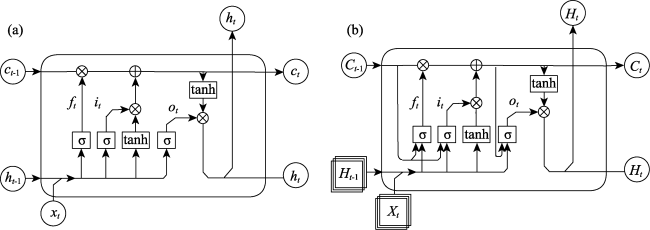
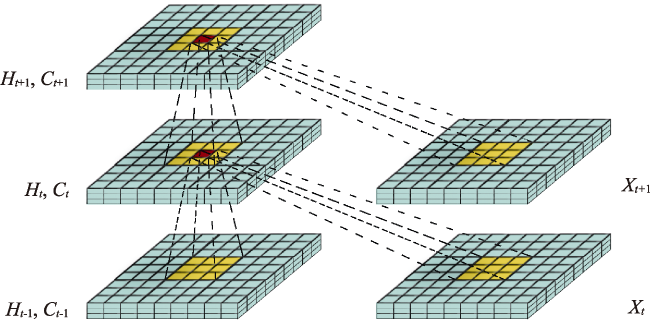
Figure 4 Cells structure of the models: (a) LSTM cells, (b) ConvLSTM cells |
Figure 5 Schematic representation of the convolution calculation of the ConvLSTM |
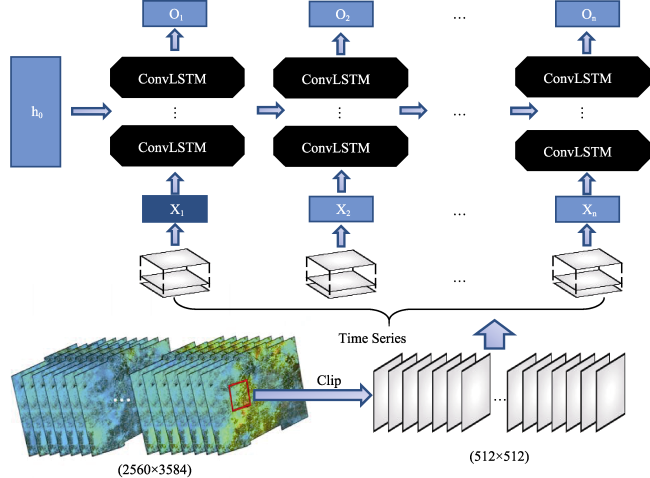
Figure 6 The stacked ConvLSTM prediction model structure |
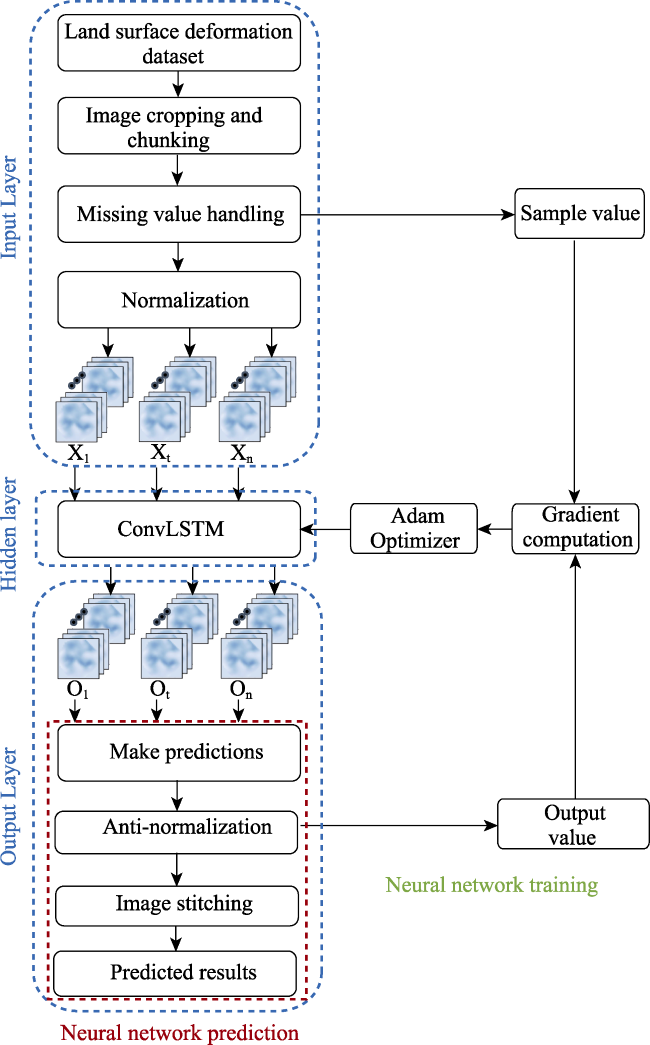
Figure 7 The flowchart of the ConvLSTM network prediction |
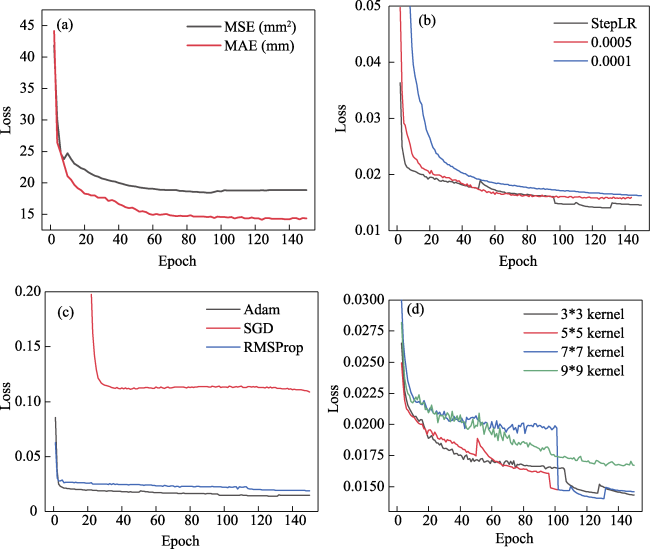
Figure 8 Parameter tuning process curve graph: (a) Loss due to various loss functions, (b) Loss due to various learning rates, (c) Loss due to various optimizers, (d) Loss due to various kernels |
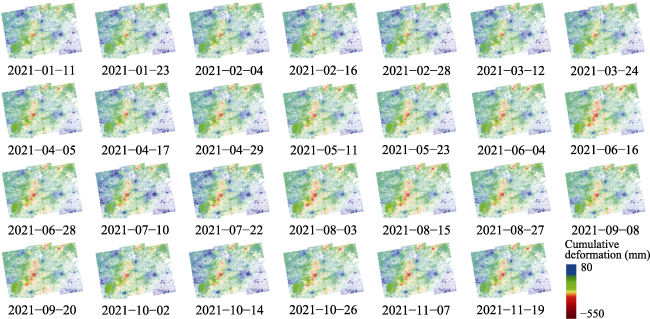
Figure 9 Cumulative shape variable forecast results for the understudied area from January 11, 2021 to November 19, 2021 |
Table 2 Evaluation of the accuracy of the prediction results |
| Model | MAE (mm) | RMSE (mm) | MSE (mm2) | SSIM | MS-SSIM |
|---|---|---|---|---|---|
| ARIMA | 17.96 | 24.06 | 597.62 | — | — |
| SVR | 16.02 | 21.31 | 470.85 | — | — |
| RNN | 14.61 | 19.46 | 393.06 | — | — |
| LSTM | 11.62 | 15.61 | 243.59 | 0.9518 | 0.9795 |
| ConvLSTM | 10.73 | 14.31 | 204.96 | 0.9654 | 0.9822 |
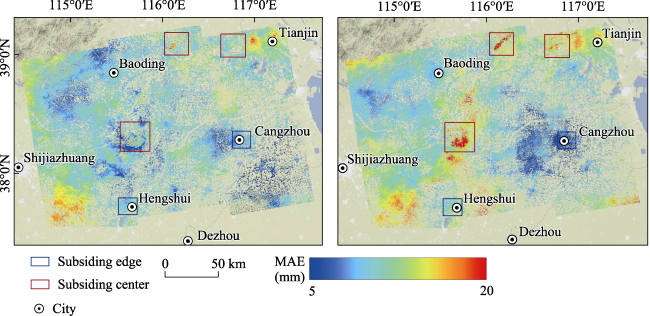
Figure 10 Comparison of MAE distributions between ConvLSTM and LSTM predictions: (a) ConvLSTM, (b) LSTM |
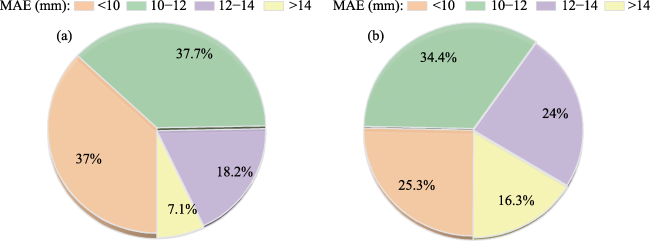
Figure 11 Comparison of MAE proportion differences between ConvLSTM and LSTM predictions: (a) ConvLSTM, (b) LSTM |
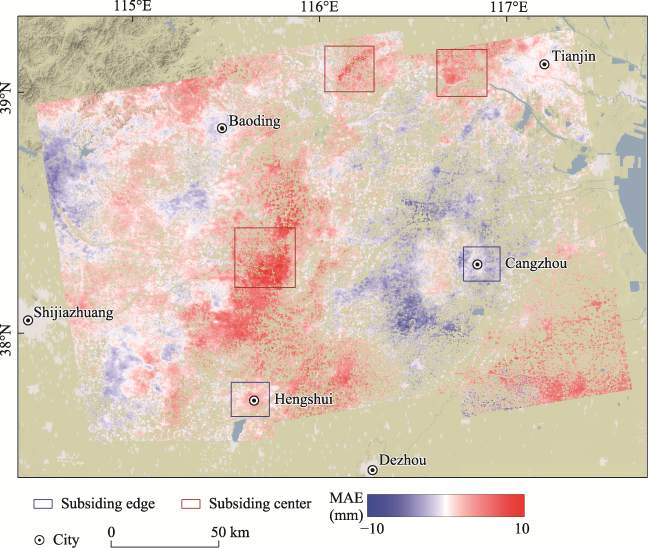
Figure 12 Distribution of MAE differences between ConvLSTM and LSTM prediction results |
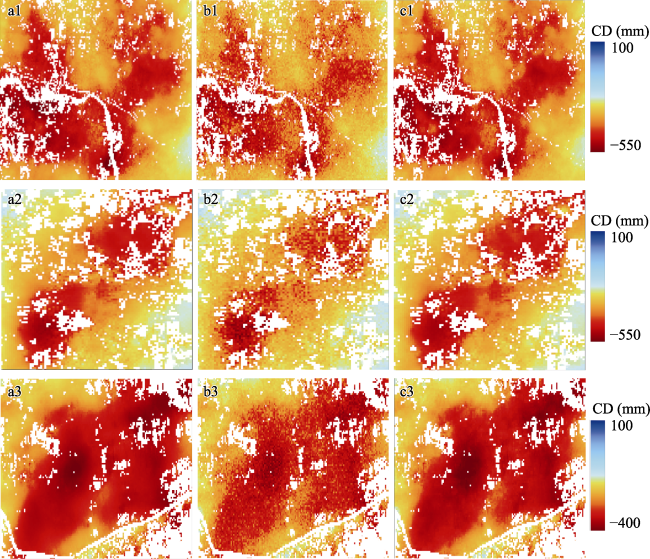
Figure 13 Spatial distribution of cumulative deformation (CD) in the subsidence center: (a) original data, (b) LSTM prediction results, (c) ConvLSTM prediction results |
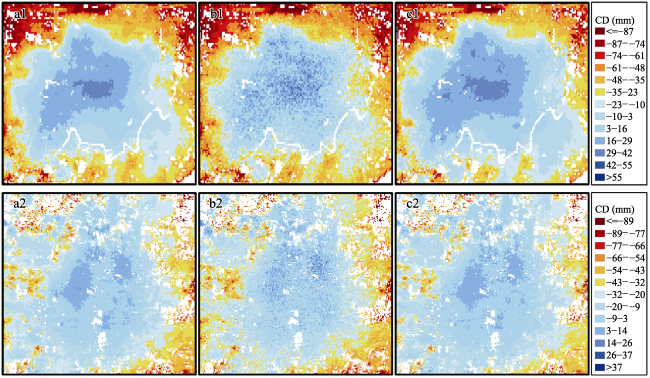
Figure 14 Spatial distribution of cumulative deformation (CD) in the subsidence edge: (a) original data, (b) LSTM prediction results, (c) ConvLSTM prediction results |
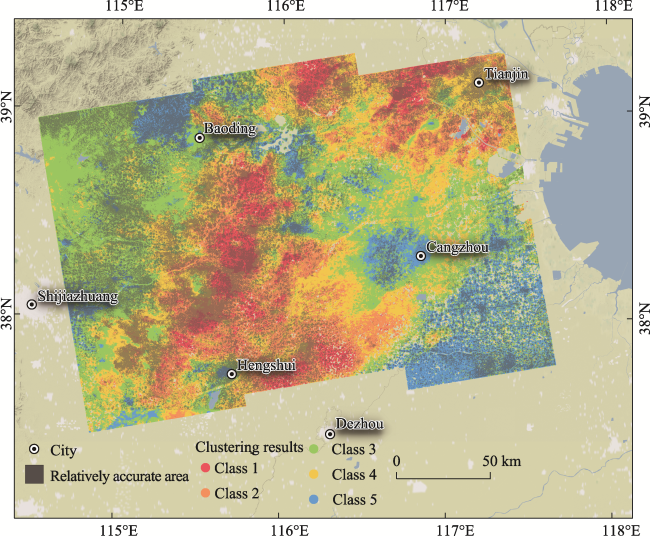
Figure 15 Clustering result of time-series subsidence data features with ConvLSTM prediction error overlay (note: the black areas indicate regions of relatively low prediction error) |
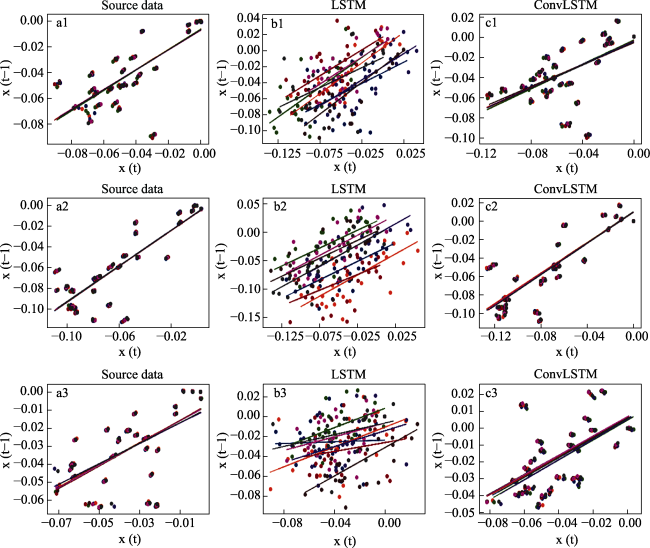
Figure 16 Autocorrelation of adjacent data points at the center of subsidence: (a) original data, (b) LSTM prediction results, (c) ConvLSTM prediction results (note: different colors represent different points of data.) |
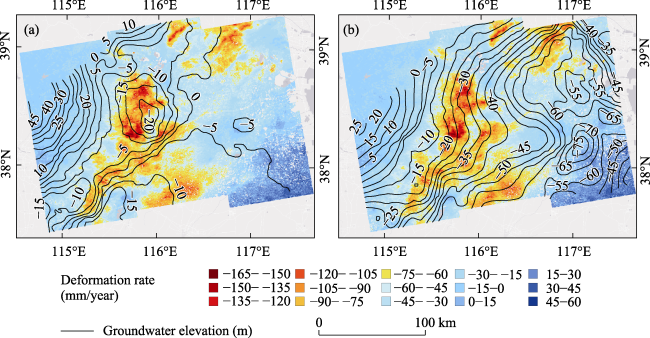
Figure 17 Distribution of groundwater decline funnel and surface settlement in the understudied area (2016): (a) elevation of the shallow groundwater table, (b) elevation of the deep groundwater table |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}