
Journal of Geographical Sciences >
Progress on spatial prediction methods for soil particle-size fractions
|
Shi Wenjiao, PhD and Professor, geographic information analysis and remote sensing of resources and environment. E-mail: shiwj@lreis.ac.cn |
Received date: 2023-05-19
Accepted date: 2023-06-09
Online published: 2023-07-24
Supported by
National Natural Science Foundation of China(41930647)
The Strategic Priority Research Program of the Chinese Academy of Sciences(XDA23100202)
The Strategic Priority Research Program of the Chinese Academy of Sciences(XDA20040301)
State Key Laboratory of Resources and Environmental Information System
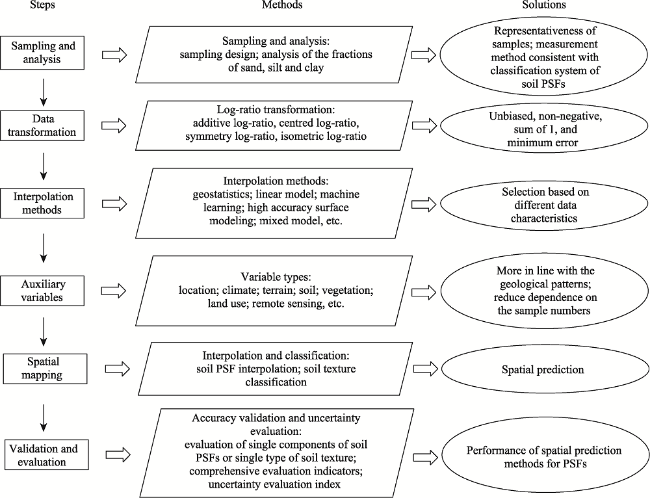
Soil particle-size fractions (PSFs), including three components of sand, silt, and clay, are very improtant for the simulation of land-surface process and the evaluation of ecosystem services. Accurate spatial prediction of soil PSFs can help better understand the simulation processes of these models. Because soil PSFs are compositional data, there are some special demands such as the constant sum (1 or 100%) in the interpolation process. In addition, the performance of spatial prediction methods can mostly affect the accuracy of the spatial distributions. Here, we proposed a framework for the spatial prediction of soil PSFs. It included log-ratio transformation methods of soil PSFs (additive log-ratio, centered log-ratio, symmetry log-ratio, and isometric log-ratio methods), interpolation methods (geostatistical methods, regression models, and machine learning models), validation methods (probability sampling, data splitting, and cross-validation) and indices of accuracy assessments in soil PSF interpolation and soil texture classification (rank correlation coefficient, mean error, root mean square error, mean absolute error, coefficient of determination, Aitchison distance, standardized residual sum of squares, overall accuracy, Kappa coefficient, and Precision-Recall curve) and uncertainty analysis indices (prediction and confidence intervals, standard deviation, and confusion index). Moreover, we summarized several paths on improving the accuracy of soil PSF interpolation, such as improving data distribution through effective data transformation, choosing appropriate prediction methods according to the data distribution, combining auxiliary variables to improve mapping accuracy and distribution rationality, improving interpolation accuracy using hybrid models, and developing multi-component joint models. In the future, we should pay more attention to the principles and mechanisms of data transformation, joint simulation models and high accuracy surface modeling methods for multi-components, as well as the combination of soil particle size curves with stochastic simulations. We proposed a clear framework for improving the performance of the prediction methods for soil PSFs, which can be referenced by other researchers in digital soil sciences.
SHI Wenjiao , ZHANG Mo . Progress on spatial prediction methods for soil particle-size fractions[J]. Journal of Geographical Sciences, 2023 , 33(7) : 1553 -1566 . DOI: 10.1007/s11442-023-2142-6
Figure 1 The framework of spatial prediction methods for soil PSFs |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}