
Journal of Geographical Sciences >
Measuring Chinese cities’ economic development with mobile application usage
|
Liu Zhewei, PhD, specialized in smart cities and spatial big data analytics. E-mail: jackie.zw.liu@connect.polyu.hk |
Received date: 2022-01-07
Accepted date: 2022-06-09
Online published: 2022-12-25
Supported by
Wuhan University State Key Laboratory of Information Engineering in Surveying Mapping and Remote Sensing(21S02)
With the rise of smart phones, mobile applications have been widely used in daily life. However, the relationship between individuals’ mobile application usage and cities’ economic development has yet to be investigated. To study this question, this work utilizes a dataset containing users’ history of mobile application usage records (MAURs) and investigates how MAURs are related to Chinese cities’ economic development. Our analysis shows the cities’ GDP and number of MAURs are highly correlated, and at the individual level, people in wealthier cities (higher GDP per capita) tend to have more active mobile application usage (MAURs per capita). The results also demonstrate the relevance between cities’ GDP and MAURs varies significantly among different demographic groups, with male users’ relevance consistently higher than female users’ and working-age people’s relevance higher than other age groups. A boosted tree regression model is then applied to predict cities’ GDP with MAURs and proves to achieve high goodness-of-fit (over 0.8 R-square) and good prediction accuracy, especially for the economically developed and populous regions in China. To the best of our knowledge, this is the first time that the relationship between MAURs and cities’ economic development is revealed, which contributes to novel knowledge discovery for regionalization and urban development.
LIU Zhewei , LIU Jianxiao , HUANG Xiao , ZHANG Erchen , CHEN Biyu . Measuring Chinese cities’ economic development with mobile application usage[J]. Journal of Geographical Sciences, 2022 , 32(12) : 2415 -2429 . DOI: 10.1007/s11442-022-2054-x
Table 1 Advantages/disadvantages of different data sources for measuring socioeconomic status |
| Data Sources | Easy access | High spatial resolution | Wide geographic coverage | Indicating individual activity | Indicating human mobility | Indicating social network |
|---|---|---|---|---|---|---|
| Satellite image | √ | √ | √ | |||
| Bank card transaction | √ | √ | √ | √ | ||
| Web-based search records | √ | √ | ||||
| Social media | √ | √ | √ | √ | √ | |
| Mobile phone call detail records (CDR) | √ | √ | √ | √ | √ |
Table 2 Attributes of the experimental datasets |
| Attributes of mobile application usage | Attributes of city’s economic development | ||
|---|---|---|---|
| Fields | Descriptions | Fields | Descriptions |
| e_id | An id uniquely indicating an event that a mobile application is used | city_name | The name of a city |
| app_id | An id uniquely indicating an application used in the event | population | The population of a city |
| u_id | An id uniquely indicating the user of the event | GDP | The GDP of a city |
| timestamp | The timestamp of the event | GDP per capita | The GDP per capita of a city |
| location | The location of the event | ||
| u_gender | The gender of the user | ||
| u_age | The age of the user | ||
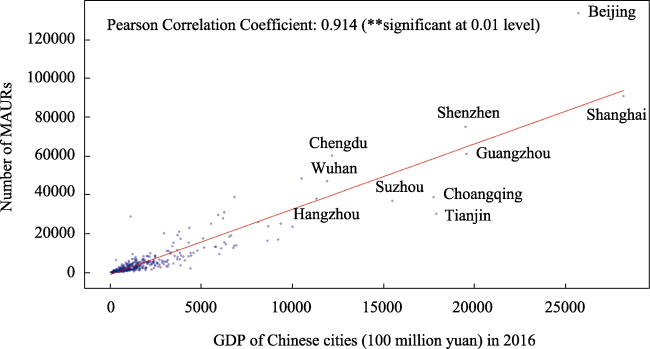
Figure 1 GDP and MAURs of Chinese cities |
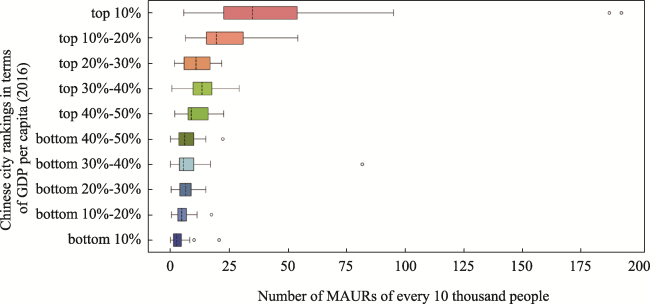
Figure 2 Boxplot of Chinese cities and their numbers of MAURs of every 10 thousand people |
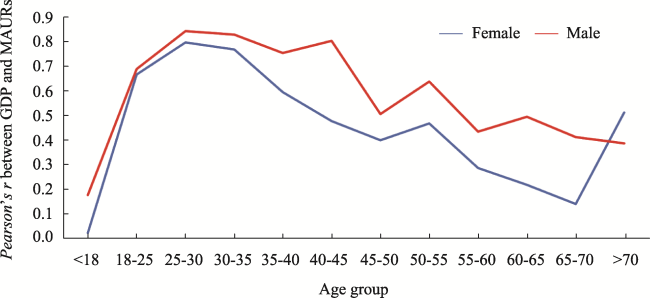
Figure 3 Correlations between cities’ GDP and MAURs of different demographic groups |
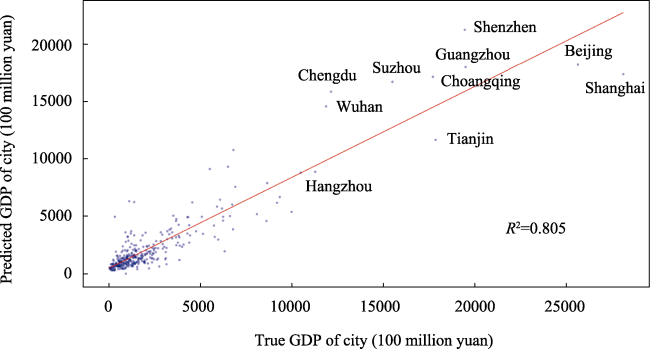
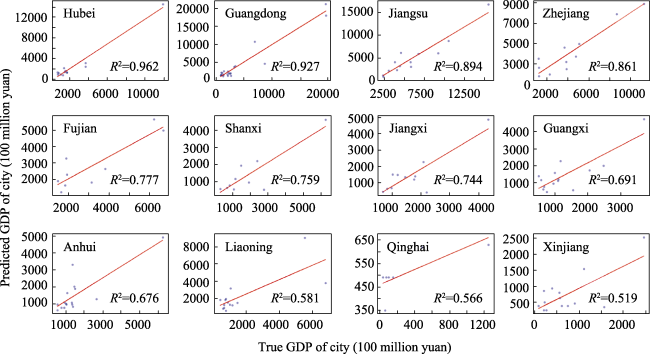
Figure 4 The regression model’s predicted GDP versus true GDP of 330 Chinese cities |
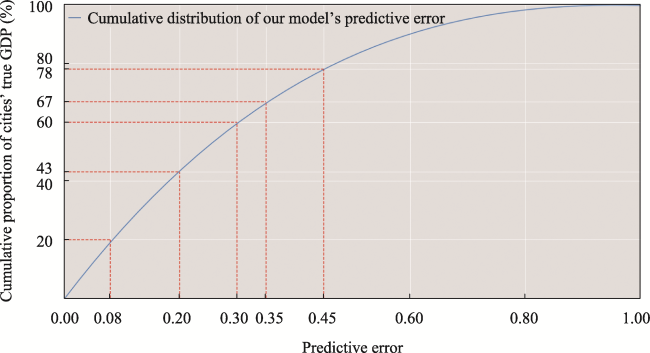
Figure 5 Cumulative distribution of our model’s predictive error |
Figure 6 The regression model’s performance over different provincial-level regions of China, measured by R2 |
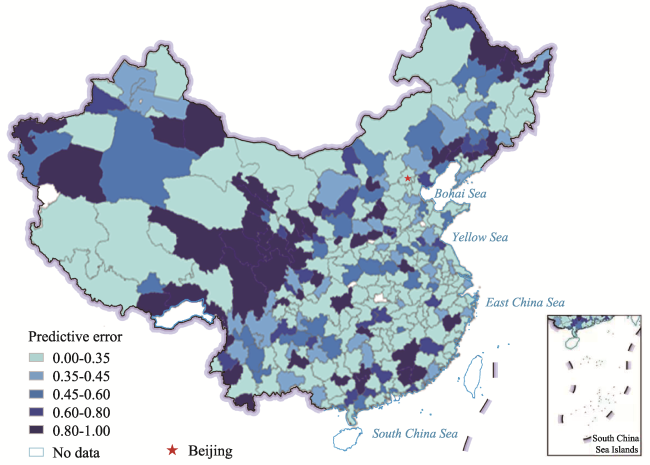
Figure 7 Each city’s predictive error in China (the cites without available data are excluded) |
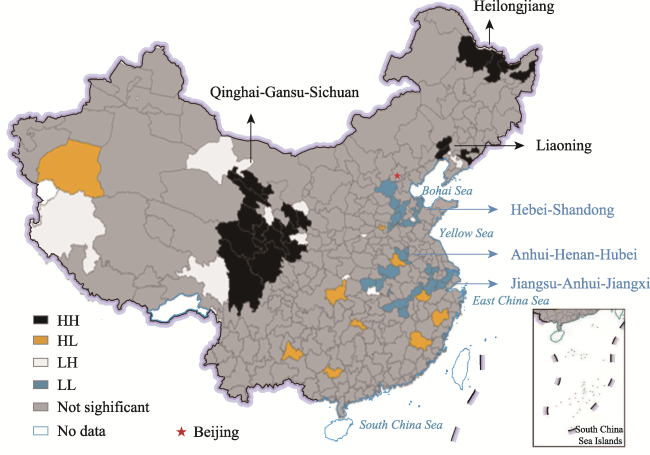
Figure 8 Four cluster types generated from Local Moran’s I of cities’ predictive errors in China |
Table 3 The correlation between cities’ predictive errors and cities’ population and GDP |
| Population | GDP | |
|---|---|---|
| Pearson’s r with predictive errors | -0.235** | -0.183** |
** significant at 0.01 level, p < 0.01. |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
TalkingData, 2016. TalkingData Mobile User Demographics. Retrieved from https://www.kaggle.com/c/talkingdata-mobile-user-demographics/overview.
|
| [35] |
TalkingData, 2020. TalkingData. Retrieved from https://www.talkingdata.com/.
|
| [36] |
|
| [37] |
|
| [38] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}