
Journal of Geographical Sciences >
Big geodata mining: Objective, connotations and research issues
|
Pei Tao (1972-), Professor, specialized in big geodata mining. E-mail: peit@lreis.ac.cn |
Received date: 2019-08-28
Accepted date: 2019-09-29
Online published: 2020-04-21
Supported by
National Natural Science Foundation of China(No.41525004)
National Natural Science Foundation of China(No.41421001)
Copyright
The objective, connotations and research issues of big geodata mining were discussed to address its significance to geographical research in this paper. Big geodata may be categorized into two domains: big earth observation data and big human behavior data. A description of big geodata includes, in addition to the “5Vs” (volume, velocity, value, variety and veracity), a further five features, that is, granularity, scope, density, skewness and precision. Based on this approach, the essence of mining big geodata includes four aspects. First, flow space, where flow replaces points in traditional space, will become the new presentation form for big human behavior data. Second, the objectives for mining big geodata are the spatial patterns and the spatial relationships. Third, the spatiotemporal distributions of big geodata can be viewed as overlays of multiple geographic patterns and the characteristics of the data, namely heterogeneity and homogeneity, may change with scale. Fourth, data mining can be seen as a tool for discovery of geographic patterns and the patterns revealed may be attributed to human-land relationships. The big geodata mining methods may be categorized into two types in view of the mining objective, i.e., classification mining and relationship mining. Future research will be faced by a number of issues, including the aggregation and connection of big geodata, the effective evaluation of the mining results and the challenge for mining to reveal “non-trivial” knowledge.
PEI Tao , SONG Ci , GUO Sihui , SHU Hua , LIU Yaxi , DU Yunyan , MA Ting , ZHOU Chenghu . Big geodata mining: Objective, connotations and research issues[J]. Journal of Geographical Sciences, 2020 , 30(2) : 251 -266 . DOI: 10.1007/s11442-020-1726-7
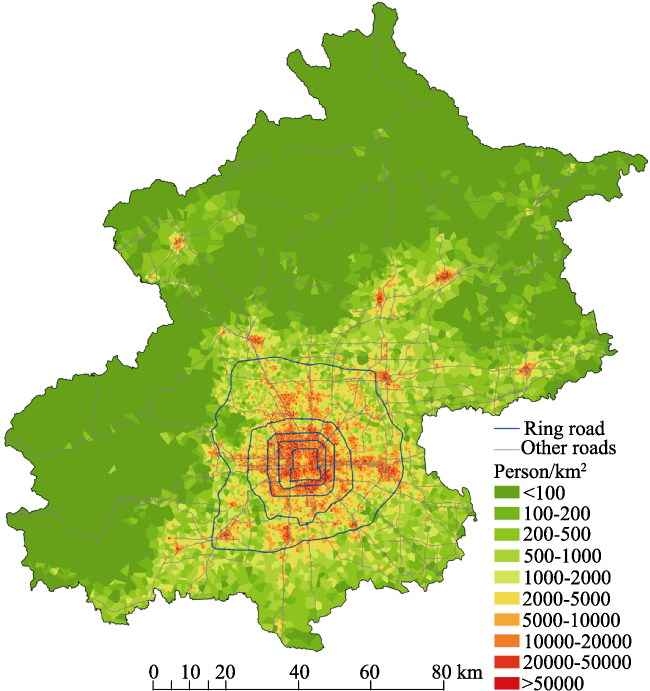
Figure 1 Fine-scale demographic estimation using mobile phone data (Liu et al., 2018) |
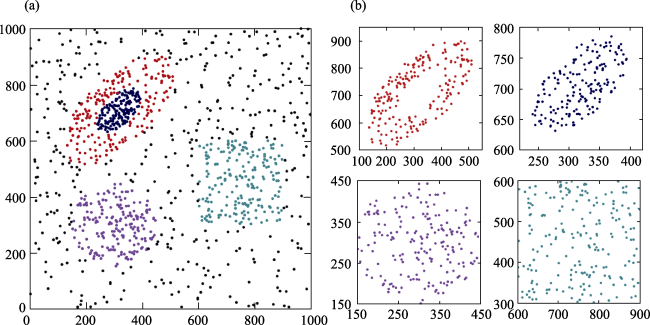
Figure 2 Transformation between homogeneity and heterogeneity of the geographical point process at difference scales: (a) heterogeneity at a large scale; (b) homogeneity at a small scale. |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
Data Center of Sina Micro-blog, 2017. 2017 User Development Report of Sina Micro-blog. in Chinese)
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
NASA, 2017. New Night Lights Maps Open Up Possible Real-Time Applications.
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
NOAA/National Centers for Environmental Information, 2018. Global Historical Climate Network Daily: Description.
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}