Since
Sheffi (2012) proposed the concept of logistics cluster, the focus of international researches has shifted from the understanding of its content and characteristics to its quantification and policy response. The major results concentrate in two areas. One is to treat cities and even larger space scope as logistics cluster and identify it with the method of per capita output value of logistics and logistics value per unit of GDP, the objects of researches are mainly located in America, Britain, Australia, Spain and Japan (
Cidell, 2010;
Prause, 2014;
Chung, 2016;
Ducret et al., 2016;
Rolkoa et al., 2017). Another is to regard well developed zone of logistics concentration, i.e., logistics bases, logistics parks and logistics industrial belts, as logistics clusters. Structure Equation Model and spatial measurement methods are adopted to explain the operation mechanism of specific logistics clusters (
Chhetri et al., 2014;
Rivera et al., 2016;
Hylton et al., 2017). For example,
Kumar et al. (2017) adopted space regression model and Spatial Autoregressive Model with Autoregressive Disturbances (SARAR) model to analyze the economic, traffic and geological data of 2008-2012 in U.S. regions and verified that logistics clusters are more concentrated in urban agglomeration and transport infrastructures have a positive influence on the transport and logistics cluster employment. In China,
Wen et al. (2005) was among the first to study logistics cluster, and later researches of other scholars were devoted to service industry clusters, transportation facilities and spatial organization of logistics enterprises etc., focusing on the identification of characteristics and connotation of logistics clusters, analysis of interaction mechanism between logistics cluster and regional economic development. However, Chinese empirical researches in this regard are comparatively weak (
Wang, 2010;
Ding et al., 2011;
Zhao et al., 2012;
Li, 2013;
Hai et al., 2016;
Pan, 2016;
Cui et al., 2017). Some differences are noted between Chinese and international researches on logistics clusters. Firstly, in researches based on administrative division, developed countries have mostly established more detailed industrial classification code and industrial development database so that the results from extraction of logistics cluster data and those of empirical studies can be compared and validated (
Rivera et al., 2016), while China’s logistics industry has not been included in the statistical classification system. Instead, statistics of transportation, warehousing and postal services are used for most of the quantitative analysis in most of the existing researches, and data in the Yellow Pages are also analyzed in some others. Thus, comparative analysis in China can hardly be performed. Secondly, in the study on the formation mechanism of logistics clusters in a particular region, questionnaires are used to obtain data in most international researches. However, the data collection standards adopted by different scholars are inconsistent and data comparison and verification are thus more difficult. Micro-scale research on logistics cluster is still in its infancy (
Qiu et al., 2013;
Hai et al., 2016). In general, the lack of research data in the logistics industry, as well as that of researches on the operation mechanism and quantitative screening of logistics clusters have restricted the deepening of theoretical and empirical researches on logistics clusters.

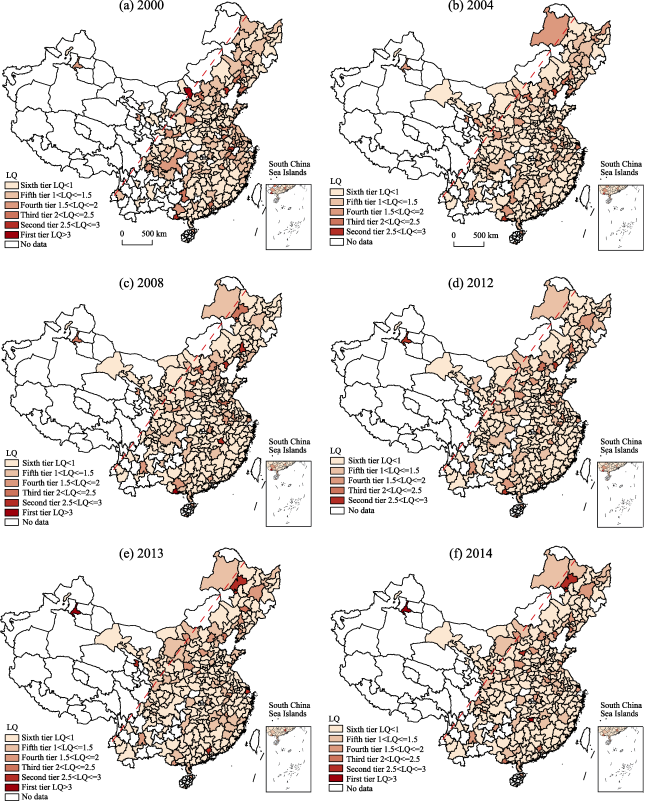
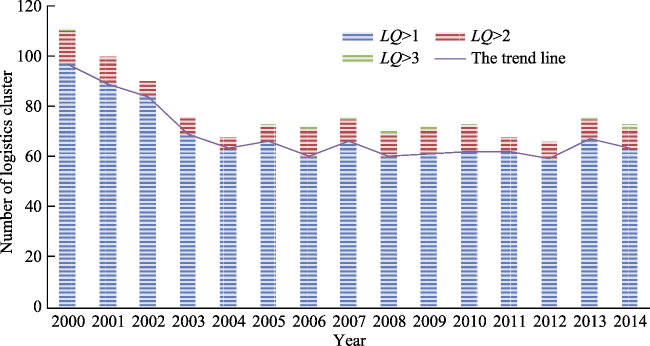
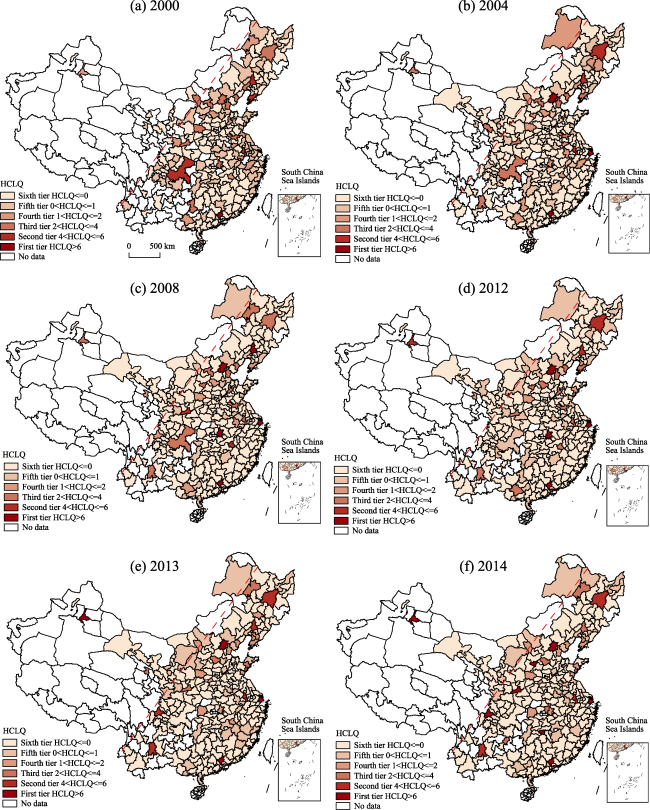
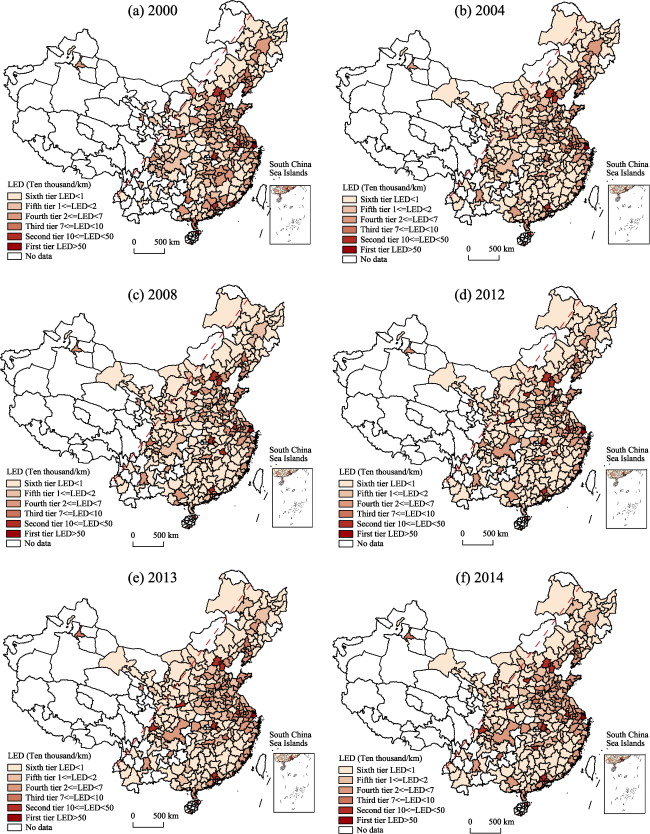
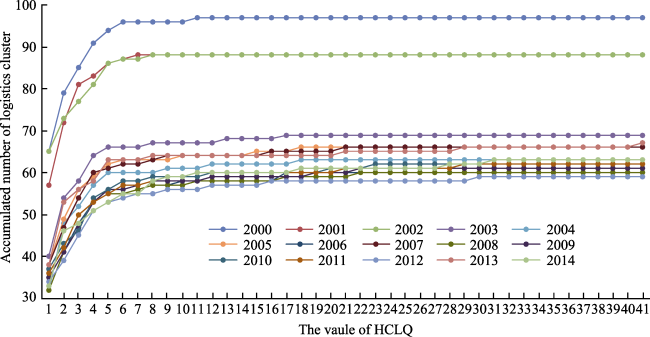
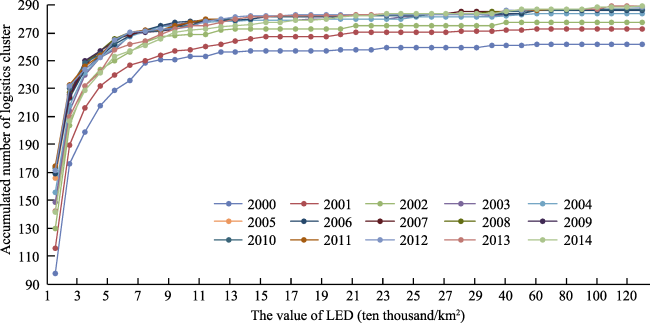
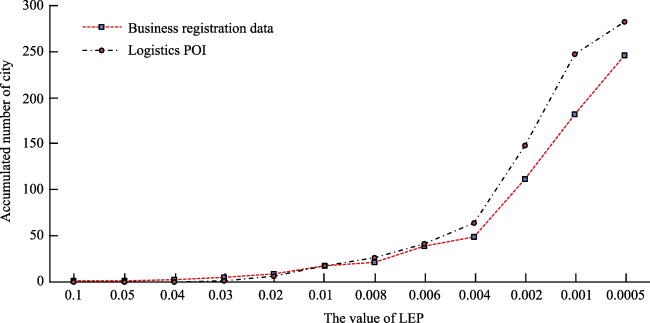
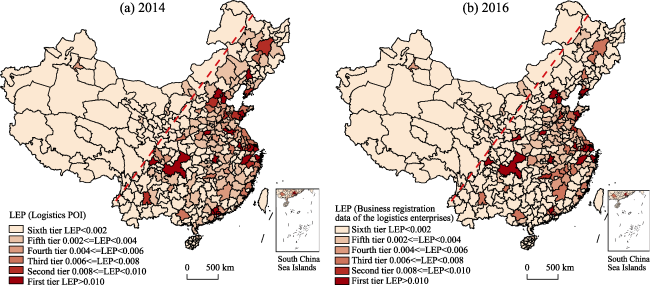
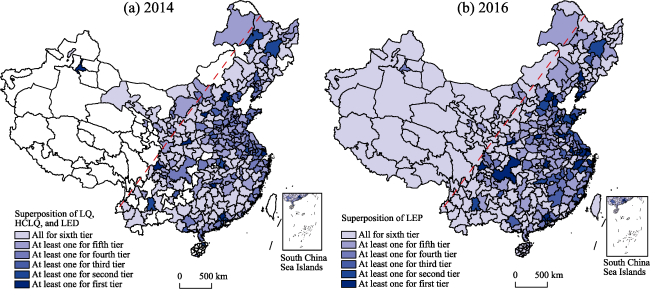
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}