
Journal of Geographical Sciences >
Location patterns of urban industry in Shanghai and implications for sustainability
Author: Cao Weidong, PhD and Professor, specialized in industrial geography. E-mail: weidongwh@163.com; 1255113766@qq.com
*Corresponding author: Cheng Jianquan, E-mail: J.cheng@mmu.ac.uk
Received date: 2016-11-22
Accepted date: 2017-01-22
Online published: 2017-07-10
Supported by
National Natural Science Foundation of China, No.41571124
Copyright
China’s economy has undergone rapid transition and industrial restructuring. The term “urban industry” describes a particular type of industry within Chinese cities experiencing restructuring. Given the high percentage of industrial firms that have either closed or relocated from city centres to the urban fringe and beyond, emergent global cities such as Shanghai, are implementing strategies for local economic and urban development, which involve urban industrial upgrading numerous firms in the city centre and urban fringe. This study aims to analyze the location patterns of seven urban industrial sectors within the Shanghai urban region using 2008 micro-geography data. To avoid Modifiable Areal Unit Problem (MAUP) issue, four distance-based measures including nearest neighbourhood analysis, Kernel density estimation, K-function and co-location quotient have been extensively applied to analyze and compare the concentration and co-location between the seven sectors. The results reveal disparate patterns varying with distance and interesting co-location as well. The results are as follows: the city centre and the urban fringe have the highest intensity of urban industrial firms, but the zones with 20-30 km from the city centre is a watershed for most categories; the degree of concentration varies with distance, weaker at shorter distance, increasing up to the maximum distance of 30 km and then decreasing until 50 km; for all urban industries, there are three types of patterns, mixture of clustered, random and dispersed distribution at a varied range of distances. Consequently, this paper argues that the location pattern of urban industry reflects the stage-specific industrial restructuring and spatial transformation, conditioned by sustainability objectives.
CAO Weidong , LI Yingying , CHENG Jianquan , Steven MILLINGTON . Location patterns of urban industry in Shanghai and implications for sustainability[J]. Journal of Geographical Sciences, 2017 , 27(7) : 857 -878 . DOI: 10.1007/s11442-017-1410-8
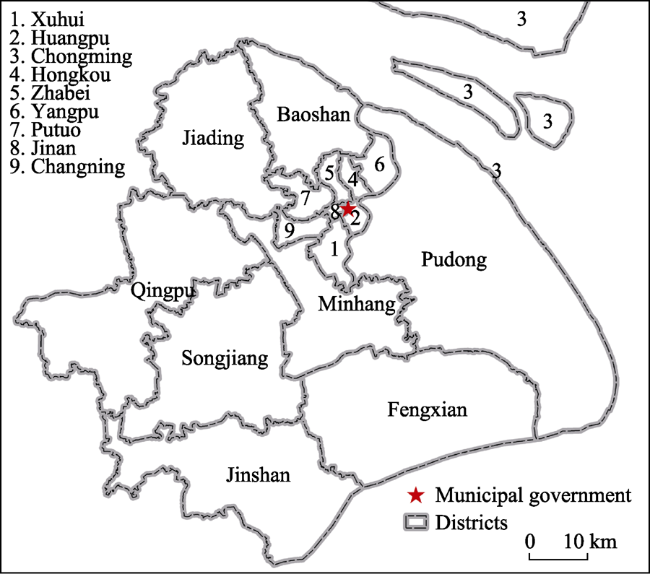
Figure 1 Location of the study area and its administrative structure |
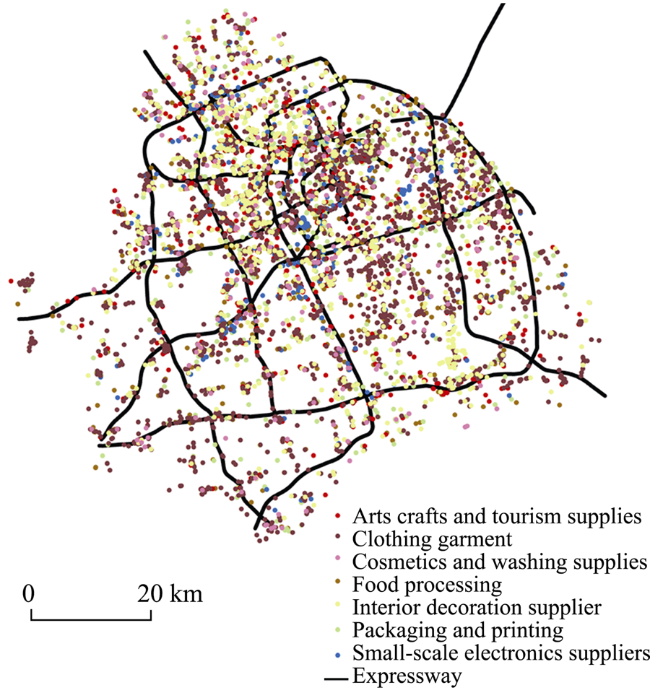
Figure 2 Spatial distribution of all urban industrial firm sites |
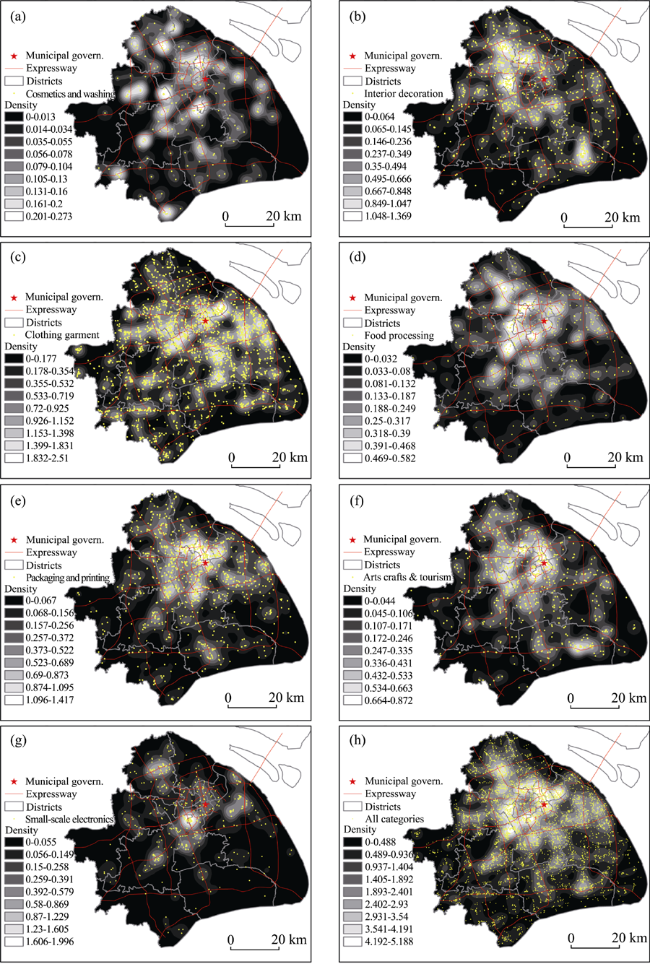
Figure 3 Kernel density of (a) Cosmetics and washing; (b) Interior decoration; (c) Clothing garment; (d) Food processing; (e) Packaging and printing; (f) Arts crafts and tourism; (g) Small-scale electronics; (h) All categories |
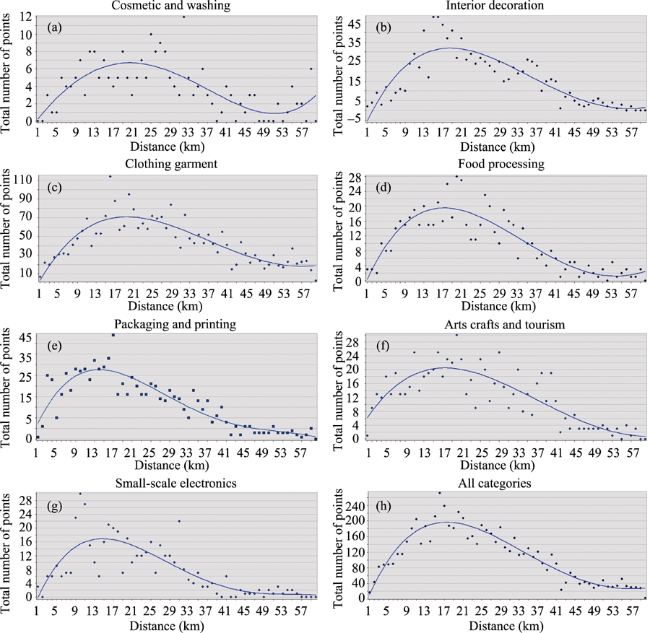
Figure 4 Relative distribution to the city centre from (a) Cosmetics and washing; (b) Interior decoration; (c) Clothing garment; (d) Food processing; (e) Packaging and printing; (f) Arts crafts and tourism; (g) Small-scale electronics; (h) All categories |
Table 1 Comparisons between categories in relative distribution to the city centre |
| Type | Peak value | Value at 100 km | Distance (km) | Decreasing rate |
|---|---|---|---|---|
| All categories | 1.29 | 0.628 | 27 | 0.0091 (7) |
| Cosmetics and washing | 1.3 | 0.642 | 29 | 0.0093 (6) |
| Interior decoration | 1.34 | 0.619 | 24 | 0.0095 (4) |
| Clothing garment | 1.24 | 0.645 | 30 | 0.0085 (8) |
| Food processing | 1.34 | 0.616 | 28 | 0.01 (2) |
| Packaging and printing | 1.39 | 0.61 | 21 | 0.0099 (3) |
| Arts crafts and tourism | 1.33 | 0.614 | 24 | 0.0094 (5) |
| Small-scale electronics | 1.42 | 0.59 | 27 | 0.011 (1) |
Table 2 Results of the nearest neighborhood analysis |
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | All |
|---|---|---|---|---|---|---|---|---|
| Observed distance | 1130 | 828 | 947 | 972 | 403 | 816 | 1997 | 231 |
| Expected distance | 2022 | 1520 | 1771 | 1918 | 963 | 1420 | 2857 | 519 |
| Ratio | 0.559 | 0.545 | 0.535 | 0.507 | 0.418 | 0.575 | 0.70 | 0.444 |
| Z-score | -20.9 | -27.36 | -23.83 | -20.22 | -57.62 | -25.25 | -8.7 | -86.23 |
| Sample size | 599 | 984 | 710 | 456 | 2643 | 958 | 224 | 6574 |
1. Food processing; 2. Packaging and printing; 3. Arts crafts and tourism; 4. Small-scale electronics; 5. Clothing garment; 6. Interior decoration; 7. Cosmetics and washing |
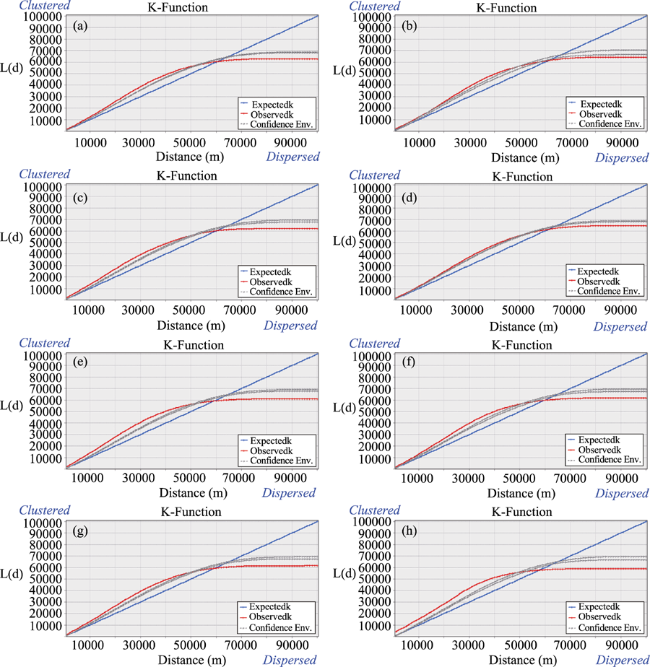
Figure 5 K-functions of (a) All; (b) Cosmetics and washing; (c) Interior decoration; (d) Clothing garment; (d) Food processing; (f) Packaging and printing; (g) Arts crafts and tourism; (h) Small-scale electronics |
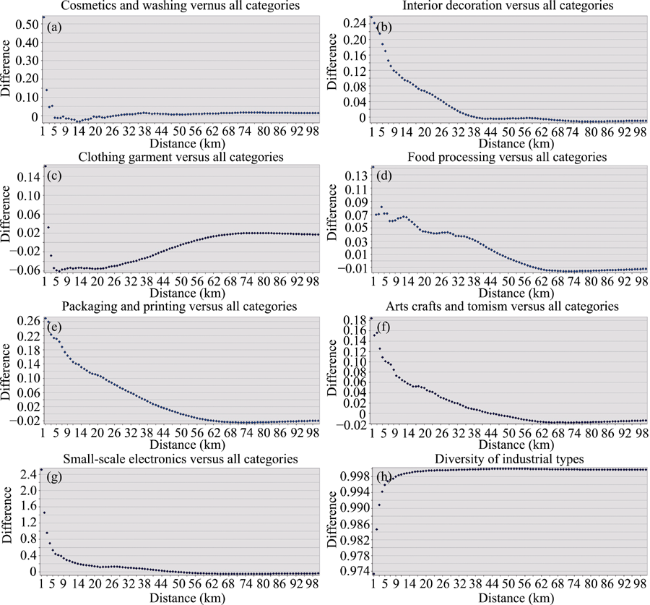
Figure 6 Comparisons with the benchmark (a) Cosmetics and washing; (b) Interior decoration; (c) Clothing garment; (d) Food processing; (e) Packaging and printing; (f) Arts crafts and tourism; (g) Small-scale electronics; (h) Diversity |
Table 3 Location pattern of each category in relation to the whole urban industry |
| Category | Significant concentration | Significant dispersion | Peak value | Peak distance |
|---|---|---|---|---|
| Cosmetics and washing | 0-4 km | - | 0.55 | 1 km |
| Interior decoration | 0-37 km | - | 0.26 | 1 km |
| Clothing garment | 0-1 & 54-100 km | 1-54 km | 0.16 & 0.02 -0.06 | 1 km, 70 km 6 km |
| Food processing | 0-54 km | 54-100 km | 0.14 -0.02 | 1 km 70 km |
| Packaging and printing | 0-50 km | 54-100 km | 0.27 -0.02 | 1 km 70 km |
| Arts crafts and tourism | 0-43 km | 43-100 km | 0.185 -0.02 | 1 km 66 km |
| Small-scale electronics | 0-44 km | - | 2.5 | 1 km |
Table 4 Co-location quotient results |
| Category | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 1 | 1.247 | 1.116 ** | 0.95 | ||||
| 2 | 1.285 | 1.066** | 0.914 | 0.923 | |||
| 3 | 1.052** | 1.339 | 0.858 | 0.913 | |||
| 4 | 0.779 | 3.56 | 0.715 | 0.771 | |||
| 5 | 0.877 | 0.859 | 0.888 | 0.71 | 1.224 | 0.835 | |
| 6 | 0.937** | 1.059* | 0.819 | 0.89 | 1.421 | ||
| 7 | 0.943** | 1.906 | |||||
| Sample | 710 | 2643 | 224 | 599 | 958 | 984 | 456 |
1. Arts crafts and tourism; 2. Clothing garment; 3. Cosmetics and washing; 4. Food processing; 5. Interior decoration; 6. Packaging and printing; 7. Small-scale electronics **: 0.05 level; *: 0.1 level; No note: 0.01 level |
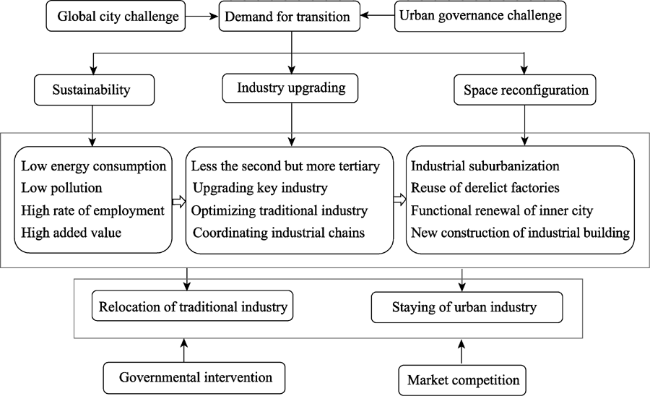
Figure 7 A conceptual framework of the emergence and layout of urban industry in Shanghai |
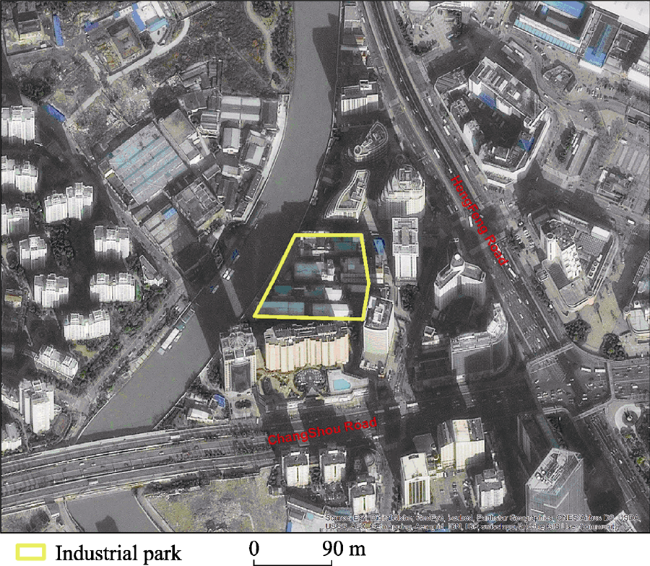
Figure 8 An example of industrial park - Buyecheng industrial park |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
Shanghai Municipal Statistics Bureau (SMSB), 2009. Shanghai Statistical Yearbook (2008). Beijing: China Statistics Press China Statistics Press.
|
| [32] |
Shanghai Municipal Statistics Bureau (SMSB), 2011. Shanghai Statistical Yearbook (2010). Beijing: China Statistics Press. .
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}